
The natural history of genetic epilepsies as told by 3,200 years of electronic medical records
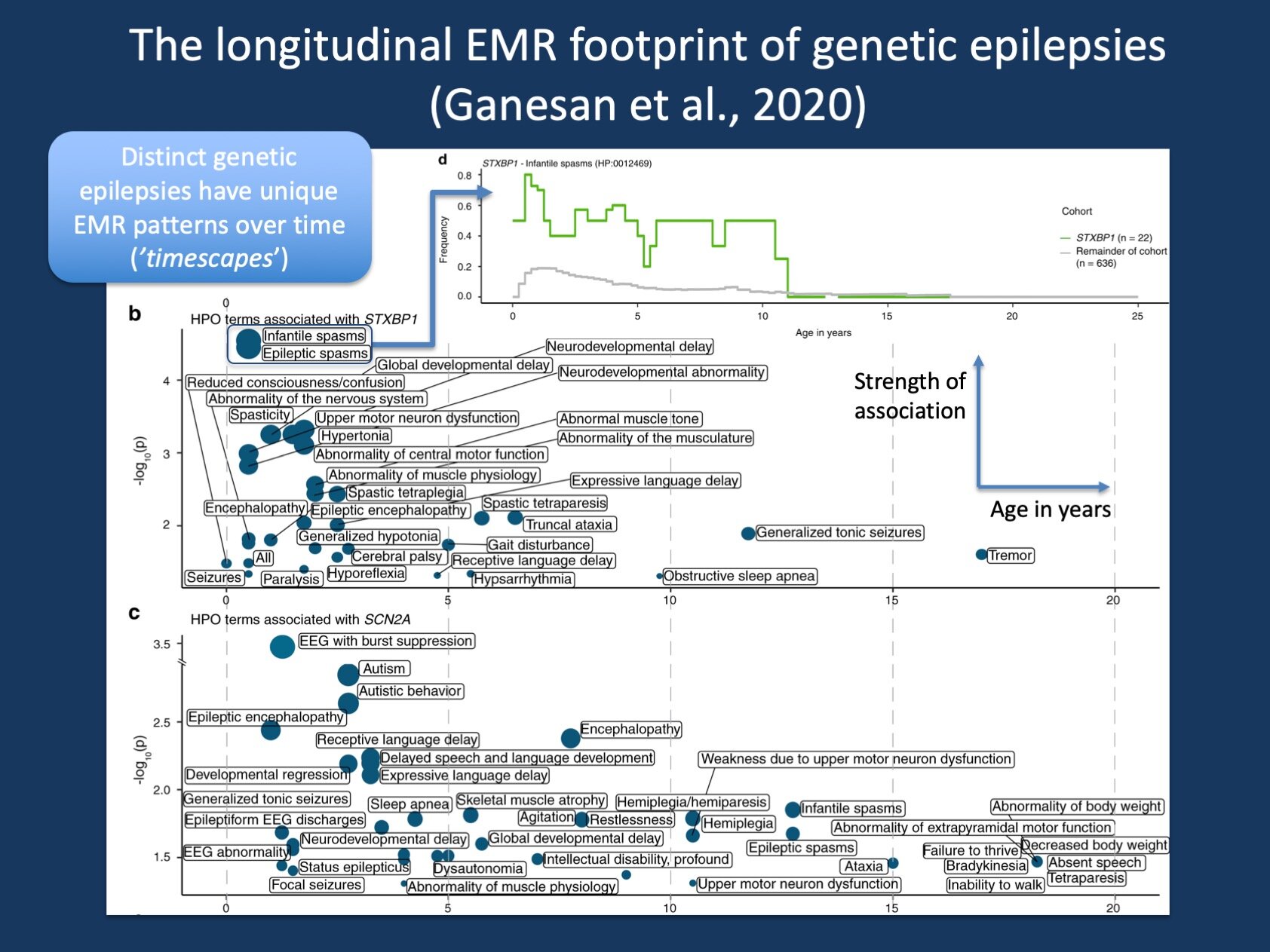
Figure 1. The timescapes of STXBP1 and SCN2A. When assessing clinical features in genetic epilepsies over time, we can assess which clinical terms are associated with a given genetic etiology at specific time points. ‘Timescapes’ are ways to visualize this complex data of 528 possible phenotypic terms across 100 time intervals. The green line at the top “decodes” the association signal of STXBP1 with Infantile Spasms, showing the frequency of Infantile Spasms over time in 22 patients with STXBP1-related disorders compared to 636 individuals in our cohort – the peak at 6 months represents the strongest association signal that is shown in the timescape plot.
Posted on August 11th, 2020 by Ingo Helbig
EMR. When we consider the natural history of rare diseases like the genetic epilepsies, we typically think about a lack of longitudinal data that contrasts with the abundant genetic information that is available nowadays – the so-called phenotyping gap. We typically suggest that we need to obtain this information in future prospective studies to better understand long-term outcome, response to medications, and potential early warning signs for an adverse disease course. However, a vast amount of clinical data is collected on an ongoing basis through electronic medical records (EMR) as a byproduct of regular patient care. In a recent study, our group built tools to mine the electronic medical records to assess the disease history of 658 individuals with known or presumed epilepsies using clinical information collected at more than 62,000 patients encounters across more than 3,200 patient years. Here is a brief summary of our first study on EMR genomics, an untapped resource that has the potential to improve our understanding of the genetic epilepsies.
A brief history of epilepsy EMR genomics. Blog posts give me the chance to tell the story behind a research study. When I started working in the US in 2014, I was impressed by the ubiquity and richness of the electronic medical records (EMR). Yes, institutions in Europe are slowly transitioning, but most relevant care is often documented outside of the EMR. In the US, the widespread adoption of EMR was mandated by the American Recovery and Reinvestment Act of 2009. By the time I started working in the US, our entire hospital was running on a single EMR platform. However, I wasn’t really thinking about the EMR as a research tool until 2016 when I almost accidentally generated a plot that showed all the clinical diagnoses of a single patient with epilepsy across two decades. Even though each diagnosis by itself did not reveal all that much, the history over time generated a pattern that was intuitive for a clinician – I was looking at the longitudinal disease history of a patient with Lennox-Gastaut Syndrome. This brief pilot experiment was so impressive to me that I started to focus my research group on making information from the EMR usable as a tool to better understand genetic epilepsies. This week marked a milestone for our lab as our first publication on EMR genomics was finally published in Genetics in Medicine.
The curse of dimensionality. EMR data is multi-dimensional, sparse and, in a nutshell, extremely difficult to work with. Therefore, the majority of our work in the last three years was conceptual, trying to build a new framework to handle and understand EMR data. What do I mean by multi-dimensional and sparse? For example, in our recent study, we were interested in clinical features to investigate natural histories and outcomes. However, there are quite a few clinical features documented in an EMR, even when we limit ourselves to neurology-related phenotypes. We found 1,479 unique neurologic diagnoses in the 658 patients included in our study. In addition, each diagnostic term is very rare in the > 62,000 patient encounters that we included, which represented the entire timeframe that was documented for our patients. To make things more complicated, patients may enter and leave our care network, or they may only have a certain age at the last observation. Our study by Ganesan et al. deals with concepts to handle this complexity in order to ask very dedicated questions, for example: “What is the most common genetic cause of Infantile Spasms?” or “What clinical features are specifically associated with SCN1A”?
A new language. We had to invent a new language to deal with EMR data that our lab has become fluent in over the last three years. Without going into too much technical detail in this post, we found ways to account for individual variability in observed time in the EMR (‘beachflag plot’, ‘EMR usage’), harmonization of phenotypic data through the Human Phenotype Ontology (‘propagation’), binning into discrete time intervals (‘snowcap plot’), and assessment of gene-specific profiles (‘timescapes’). In brief, we were able to take the sparse and multidimensional EMR data, translate this data into a common language that connects all phenotypic terms, and assess the link of clinical features with genetic etiologies in 100 time intervals (3-months) between birth and age 25. Our lab codename for this project was “The Cube,” based on the three-dimensional data arrays we used to store the harmonized data for further analysis (patient time clinical feature). This transformed data now allowed us to ask relatively straightforward questions, for example “For how many patients do we have EMR data at the age of 6 months?” (answer: 201/658); “What percentage of patients have Infantile Spasms at this age?” (answer: 38/200 = 19%).
Introducing complexity. As we had genetic information on all 658 individuals, we could then ask a second set of questions: “Which gene has the most prominent association with Infantile Spasms and when is this association the strongest?” (answer: STXBP1 at 6 months); “What is the most significant association with SCN1A?” (answer: status epilepticus at 12 months). And finally, we could move up towards more complex questions, such as “What is the overall profile of SCN2A in the EMR?” This question is not easily answerable in a single sentence as we found 859 nominally significant associations between clinical features and genetic changes and 57 nominally significant associations with SCN2A. To help with this complexity, we developed ‘timescape plots’ to visualize this information. The lower part of the figure in this blog post (see above) provides a visual overview of the longitudinal profile of STXBP1 and SCN2A, demonstrating the various terms associated with both genes and highlighting the time interval with the strongest association. This now gives us a good toolkit to handle complex EMR data. The figure in our blog post is derived from Figure 4 and Figure 5 from our publication.
Face value. There are certain aspects of EMR data that people are rightfully skeptical about – diagnoses are often copied forward and frequently not taken off when no longer applicable. In our study, we examined the clinical profile of several genetic epilepsies at face value. While some data inaccuracy is undeniable, overall, the distribution of individual clinical features (Figure 3) and the clinical “footprint” of specific genetic epilepsies paralleled our clinical experience with these conditions. This means that despite all limitations, EMR data works unexpectedly well. We could reproduce many of the known clinical features of distinct genetic epilepsies in our study. Our automated analysis of EMR data enabled us to rebuild longitudinal natural histories of 36 causative genes identified in two or more individuals. The most common genetic etiologies in our cohort included SCN1A (n = 29), STXBP1 (n = 22), SCN2A (n = 12), KCNQ2 (n = 8), and KCNT1 (n = 6). The number of individuals contributing to each of the 100 time intervals ranged from 5 to 266 with a median of 142 individuals per time point. EMR usage in the cohort was highest between age 2 and age 7, generating a ridge-shape distribution (Figure 2C in our publication).
The novelty. We believe that we have shown that EMR data allows us to recapitulate longitudinal disease histories in the genetic epilepsies, giving us a new tool to accompany natural history studies. We demonstrate that we can use the EMR to transform clinical data into a computable format – and that this framework is easily scalable. We demonstrate that this data has face value, and it presents the first step towards clinical decision support systems and learning healthcare systems. This is a major step that allows us to generate clinical data where natural history studies may be limited. We can compare across diseases, match profiles of various genetic epilepsies and look across the entire documented timespan – using amounts of data that are far beyond the ability of manual phenotyping.
What you need to know. We wanted to know whether EMR data can be meaningfully used to capture some clinical aspects of the genetic epilepsies. The answer is: absolutely yes. Once we generated concepts and built tools to overcome the inherent complexity EMR data, we were able to use this information to assess the development of phenotypes over time far beyond what is humanly possible. We identify gene-specific profiles based on a vast data source far beyond the capability of human phenotyping, which will be a critical step towards using this data for EMR-based decision tools and natural history studies that will allow us to better understand how clinical features in genetic epilepsies develop over time.